
How To Ace The Data Science Interview

There’s no way around it. Technical interviews can seem harrowing. Nowhere, I would argue, is this more true than in data science. There’s just so much to know.
What if they ask about bagging or boosting or A/B testing?
What about SQL or Apache Spark or maximum likelihood estimation?
Unfortunately, I know of no magic bullet that’ll prepare you for the breadth of questions you’ll be up against. Experience is all you’ll have to rely upon. However, having interviewed scores of applicants, I can share some insights that will make your interview smoother and your ideas clearer and more succinct. All this so that you’ll finally stand out amongst the ever growing crowd.
Without further ado, here are interviewing tips to make you shine:
- Use Concrete Examples
- Know How To Answer Ambiguous Questions
- Choose The Best Algorithm: Accuracy vs Speed vs Interpretability
- Draw Pictures
- Avoid Jargon or Concepts You’re Unsure Of
- Don’t Expect To Know Everything
- Realize An Interview Is A Dialogue, Not A Test
Tip #1: Use Concrete Examples
This is a simple fix that reframes a complicated idea into one that’s easy to follow and grasp. Unfortunately, it’s an area where many interviewees go astray, leading to long, rambling, and occassionally nonsensical explanations. Let’s look at an example.
Interviewer: Tell me about K-means clustering.
Typical Response
K-means clustering is an unsupervised machine learning algorithm that segments data into groups. It’s unsupervised because the data isn’t labeled. In other words, there is no ground truth to speak of. Instead, we’re trying to extract underlying structure from the data, if indeed it exists. Let me show you what I mean. [draws image on whiteboard]
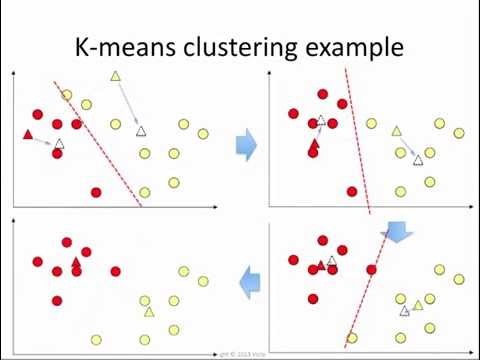
The way it works is simple. First, you initialize some centroids. Then you calculate the distance of each data point to each centroid. Each data point gets assigned to its nearest centroid. Once all data points have been assigned, the centroid is moved to the mean position of all the data points within its group. You repeat this process until no points change groups.
What Went Wrong?
On the face of it, this is a solid explanation. However, from an interviewer’s perspective there are several issues. First, you provided no context. You spoke in generalities and abstractions. This makes your explanation harder to follow. Second, while the whiteboard drawing is helpful, you did not explain the axes, how to choose the number of centroids, how to initialize, and so on. There’s so much more information that you could have included.
Better Response
K-means clustering is an unsupervised machine learning algorithm that segments data into groups. It’s unsupervised because the data isn’t labeled. In other words, there is no ground truth to speak of. Instead, we’re trying to extract underlying structure from the data, if indeed it exists.
Let me give you an example. Say we’re an advertising firm. Up to this point we’ve been showing the same online ad to all viewers of a given website. We think we can be more effective if we can find a way to segment those viewers to send them targeted ads instead. One way to do this is through clustering. We already have a way to capture a viewer’s income and age. [draws image on whiteboard]
The x-axis is age and y-axis is income in this case. This is a simple 2D case so we can easily visualize the data. This helps us choose the number of clusters (which is the ‘K’ in K-means). It looks like there are two clusters so we will initialize the algorithm with K=2. If visually it wasn’t clear how many K to choose or if we were in higher dimensions, we could use inertia or silhouette score to help us hone in on the optimal K value. In this example, we’ll randomly inititalize the two centroids, though we could have chosen K++ initialization as well.
Distance between each data point to each centroid is calculated and each data point gets assigned to its nearest centroid. Once all data points have been assigned, the centroid is moved to the mean position of all the data points within its group. This is what’s depicted in the top left graph. You can see the centroid’s initial location and the arrow showing where it moved to. Distances from centroids are again calculated, data points reassigned, and centroid locations get updated. This is shown in the top right graph. This process repeats until no points change groups. The final output is shown in the bottom left graph.
Now we have segmented our viewers so we can show them targeted advertisements.
Takeaway
Have a toy example ready to go to explain each concept. It could be something similar to the clustering example above or it could relate how decision trees work. Just make sure you use real-world examples. It shows not only that you know how the algorithm works but that you know at least one use case and that you can communicate your ideas effectively. Nobody wants to hear generic explanations; it’s boring and makes you blend in with everyone else.
Tip #2: Know How To Answer Ambiguous Questions
From the interviewer’s perspective, these are some of the most exciting questions to ask. It’s something like:
Interviewer: How do you approach classification problems?
As an interviewee, before I had the chance to sit on the other side of the table, I thought these questions were ill posed. However, now that I’ve interviewed scores of applicants, I see the value in this type of question. It shows several things about the interviewee:
- How they react on their feet
- If they ask probing questions
- How they go about attacking a problem
Let’s look at a concrete example:
Interviewer: I’m trying to classify loan defaults. Which machine learning algorithm should I use and why?
Admittedly, not much information is provided. That is usually by design. So it makes perfect sense to ask probing questions. The dialogue may go something like this:
Me: Tell me more about the data. Specifically, which features are included and how many observations?
Interviewer: The features include income, debt, number of accounts, number of missed payments, and length of credit history. This is a big dataset as there are over 100 million customers.
Me: So relatively few features but lots of data. Got it. Are there any constraints I should be aware of?
Interviewer: I’m not sure. Like what?
Me: Well, for starters, what metric are we focused on? Do you care about accuracy, precision, recall, class probabilities, or something else?
Interviewer: That’a great question. We’re interested in knowing the probability that someone will default on their loan.
Me: Ok, that’s very helpful. Are there any constraints around interpretability of the model and/or the speed of the model?
Interviewer: Yes, both actually. The model has to be highly interpretable since we work in a highly regulated industry. Also, customers apply for loans online and we guarantee a response within a few seconds.
Me: So let me just make sure I understand. We’ve got just a few features with lots of records. Furthermore, our model has to output class probabilities, has to run quickly, and has to be highly interpretable. Is that correct?
Interviewer: You’ve got it.
Me: Based on that information, I would recommend a Logistic Regression model. It outputs class probabilities so we can check that box. Additionally, it’s a linear model so it runs much more quickly than lots of other models and it produces coefficients that are relatively easy to interpret.
Takeaway
The point here is to ask enough pointed questions to get the necessary information you need to make an informed decision. The dialogue may go lots of different ways but don’t hesitate to ask clarifying questions. Get used to it because it’s something you’ll have to do on a daily basis when you’re working as a DS in the wild!
Tip #3: Choose The Best Algorithm: Accuracy vs Speed vs Interpretability
I covered this implicitly in Tip #2 but any time someone asks you about the merits of using one algorithm over another, the answer almost always boils down to pinpointing which 1 or 2 of the 3 characteristics - accuracy or speed or interpretability - are most important. Note, it’s usually not possible to get all 3 unless you have some trivial problem. I’ve never been so fortunate. Anyway, some situations will favor accuracy over intrepretability. For example, a deep neural net may outperform a decision tree on a certain problem. The converse can be true as well. See No Free Lunch Theorem. There are some circumstances, especially in highly regulated industries like insurance and finance, that prioritize interpretability. In this case, it’s completely acceptable to give up some accuracy for a model that’s easily interpretable. Of course there are situations where speed is paramount too.
Takeaway
Whenever you’re answering a question about which algorithm to use, consider the implications of a particular model with regards to accuracy, speed, and intrepretability. Let the constraints around these 3 characteristics drive your decision about which algorithm to use.
Tip #4: Draw Pictures

This should go without saying - should being the operative word. Most interviewees make good use of the whiteboard or a piece of paper but occassionally I interview someone who tries to explain everything in words. That makes for a bad experience, let me tell you. We’ve all heard the old adage “a picture is worth a thousand words”. And it’s so true. Applying this technique can turn a five minute rambling explanation into a 10-second drawing and a 30-second explanation. Remember, the whiteboard is your friend. Use it!
A few things to keep in mind when drawing pictures:
- Label your axes
- Explain your axes
- Stay in 2D (unless you’re an artist; I’ve seen too many people crash and burn drawing in 3D)
- Use different shapes to denote different classes or clusters (e.g. triangles for class 0; circles for class 1)
- Use different colors for classification or clustering if possible
- Vocalize what you’re doing while you’re doing it (it helps me follow because I haven’t perfected my mind reading skills yet)
Tip #5: Avoid Jargon or Concepts You’re Unsure Of
This is hands down the easiest way to sabotage yourself. I see it all the time. Here’s the situation. You’re deep in your explanation of how gradient descent (GD) works and things are going smoothly, so you decide to reach a little and mention Elastic Net when describing GD and regularization, even though you’re not very confident in how Elastic Net works or exactly what it is. But things were going great and you want to show how smart you are. You can slip this in and nobody will notice, right? Not a chance! Thing is, you don’t notice how painfully obvious it is to the interviewer that you don’t know this term. Your voice quivers or your face contorts when you let slip the word Elastic Net. It’s likely imperceptible to you but not to us. What happens? The moment you’re done talking I effortlessly expose your weakness thus dismantling your explanation piece by piece.
Am I being a jerk? Some people may think so. But consider this: if I hire you, odds are you’ll have to defend a model or platform to hardcore techies or C-level execs. Imagine you pull the same stunt. Things are going well, you’re explaining the pros of your model, and then you let slip this slippery term you haven’t quite come to grips with. Now it’s not me that’s going to pick you apart, it’s one of them. And once you fail to explain this term, you lose all credibility. Your model or platform is kaput. So this is really an exercise in communication. You need to foster credibility and you do that by exhibiting knowledge.
Tip #6: Don’t Expect To Know Everything
In my opinion, a good technical interview is one where I, as the interviewer, can find the limits of your knowledge. And you better believe I’m going to take you to that limit. Sometimes it only takes 2-3 questions to find someone’s limit and sometimes it takes delving into some esoteric edge case that’s 10 questions deep. Sometimes it’s even asking questions that I don’t know the answer to but I can follow your logic and study your body language to see if there’s a good chance that you do. Plus, I have the luxury of looking up the answer later to check my intuition.
The point is that if you walk out of an interview feeling down because you weren’t able to answer every question, you should rethink your expectations. A good interviewer will most definitely take you just beyond your limits. Instead, focus on the types of questions you got wrong. Did you miss a bunch of easy questions? Then that’s on you. Did you miss a question about advantages and disadvantages of using OVA Binomial vs Multinomial Logistic Regression? Probably not a big deal and you walk away with something new to learn.
Tip #7: Realize An Interview Is A Dialogue, Not A Test
Most everyone walks into a technical interview thinking all they have to do is answer all the questions correctly and then they’re home free. Nope! Even if you magically pull that off (see Tip #6), the interviewer is looking at more than just your technical knowledge. There’s a very good chance the interviewer could be your boss or co-worker, which means you’ll be spending lots of time together. That also means you’re being evaluated for fit. Maybe you’re high energy but the group is mostly introverted. That would mess with the dynamics so you’re a no-go. It could be that the interviewer is one of those people that’s “always right” and will not tolerate a challenge, even if it’s warranted. Who knows, maybe your personalities clash. It happens. But it’s better to find that out sooner rather than later.
So the first 6 tips built you up and now it appears I’m telling you it may be hopeless after all. Far from it. The key here is that an interview is a two-way street. Can you be eliminated for any number of serious or silly reasons, even if you have all the technical skills? Absolutely. But the fact is that you have an equal amount of power. You should treat the interview not as a test but as a dialogue; you are interviewing this employer as much as they are interviewing you. If the interviewer is a jerk or has a massive ego or you see some other red flag, don’t discount it. You should step back and consider if you really want to work there.
And trust me, I get it. You may have been out of work for awhile and the sound of a paycheck sounds mighty nice right about now. And maybe this is your best play. But assuming you have a little breathing room, seriously consider the anguish you’ll experience working for the jerk across the table. Having a paycheck but working full-time, feeling miserable, and having to add a job search on top of all that is no easy feat. In sum, ask questions, document those red flags, and choose wisely. When you find the right job and the right culture, you’ll know it immediately.
Summary
Having strong technical skills will get you far in many industries but can leave you empty-handed in data science. Here are some ways you can stand out:
- Use Concrete Examples
- Know How To Answer Ambiguous Questions
- Choose The Best Algorithm: Accuracy vs Speed vs Interpretability
- Draw Pictures
- Avoid Jargon or Concepts You’re Unsure Of
- Don’t Expect To Know Everything
- Realize An Interview Is A Dialogue, Not A Test